
5 Ways to Improve Your API Reliability

APIs make our digital world tick, allowing diverse applications talk to each other. However, the reliability of these APIs is critical for ensuring seamless functionality and performance of applications that depend on them. In this blog post, we'll explore five key strategies to improve your API reliability.

1. Implement Robust Testing Practices
The first line of defense in ensuring API reliability is comprehensive testing. This includes functional testing to verify the correct operation of individual APIs, integration testing to ensure APIs work correctly in combination with other systems, and load testing to understand how the API behaves under heavy usage.
Automated tests can help catch issues early in the development cycle, and regression tests can ensure that new changes don't break existing functionality. The use of virtualization or mocking techniques can simulate API dependencies for more comprehensive testing. Additionally, contract testing is important to ensure that both the provider and consumer of the API are meeting the agreed-upon interface.
let's look at how we might perform a simple test on a hypothetical API endpoint using Go's built-in testing package.
Assume we have an endpoint GET /users/{id}, which returns the details of a user. Here's how we might write a test for it:
package main
import (
"net/http"
"net/http/httptest"
"testing"
)
// This is a simplified function that your actual handler might look like
func UserHandler(w http.ResponseWriter, r *http.Request) {
// ... handler logic
}
func TestUserHandler(t *testing.T) {
req, err := http.NewRequest("GET", "/users/1", nil)
if err != nil {
t.Fatal(err)
}
rr := httptest.NewRecorder()
handler := http.HandlerFunc(UserHandler)
handler.ServeHTTP(rr, req)
if status := rr.Code; status != http.StatusOK {
t.Errorf("handler returned wrong status code: got %v want %v",
status, http.StatusOK)
}
// You can also check the response body with expected output
expected := `{"id": "1", "name": "John Doe"}`
if rr.Body.String() != expected {
t.Errorf("handler returned unexpected body: got %v want %v",
rr.Body.String(), expected)
}
}
This test creates a new HTTP request that mimics a call to our /users/{id} endpoint, then it passes that request to the handler function. The test checks if the response status is 200 OK (which is what we expect for a successful request) and if the response body matches the expected output.
This is a simple example, in a real-world application, you would have more complex scenarios including testing various edge cases, error paths, and so forth. Also, the net/http/httptest package provides more tools for testing HTTP clients and servers.
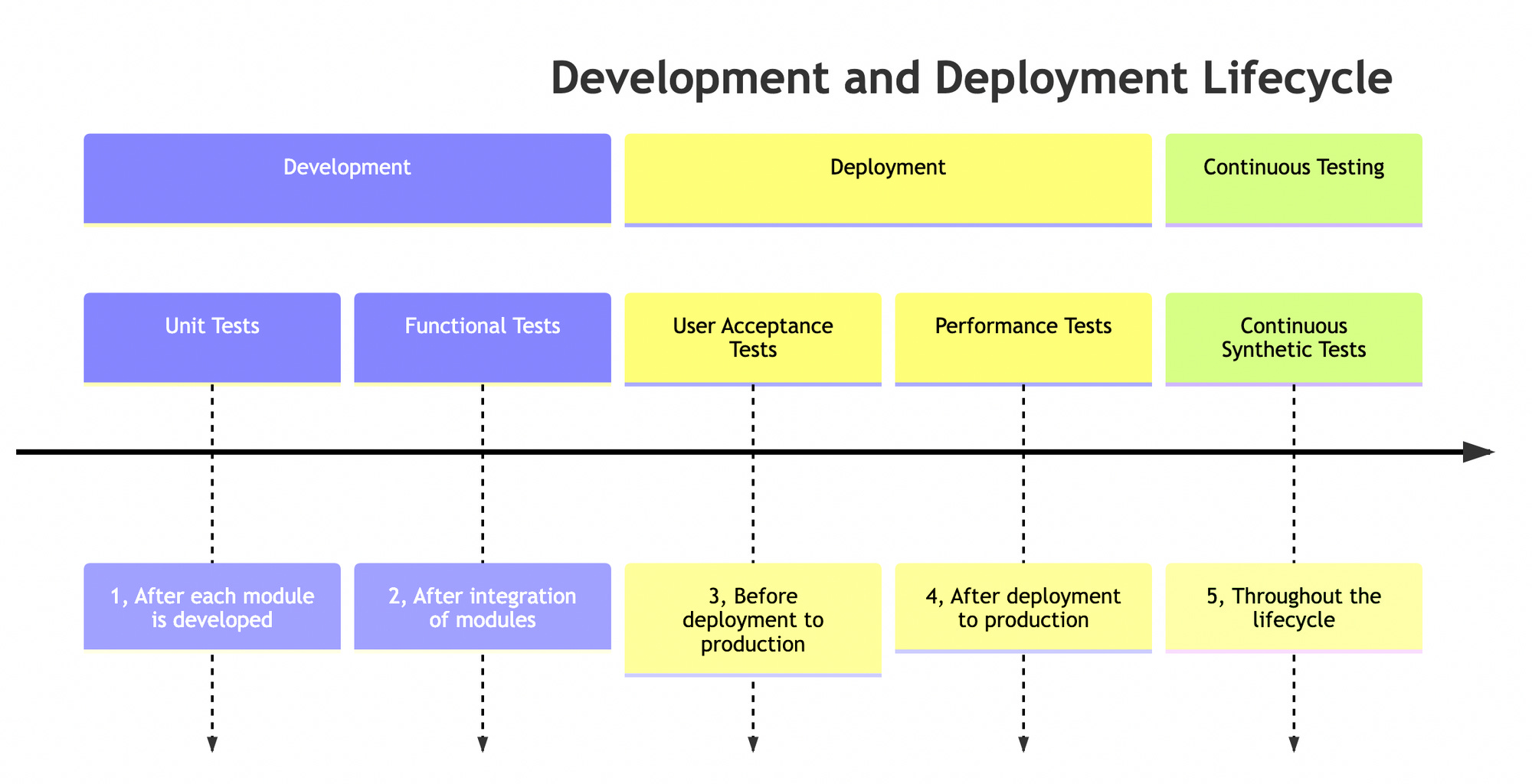
In addition, you can combine this with unit tests, performance tests, and continuous synthetic tests, thereby creating a comprehensive testing suite for your API.
Unit tests help in ensuring the correctness of individual components within your API. By isolating each part and verifying its functionality, you can identify and rectify problems at an early stage. Unit testing can be done by mocking dependencies and testing the functions in isolation. In Go, this can be achieved with the help of packages like testify.
Performance tests, on the other hand, are designed to stress test your API under load conditions. They help in determining how the system behaves under heavy loads, identify bottlenecks, and ensure that the API can handle real-world use. Tools such as JMeter or Gatling can be used to conduct performance tests.
Lastly, continuous synthetic tests run a sequence of operations on your API continuously to simulate the journey of a user or a client through your system. These tests can provide insights into end-to-end workflows, potential roadblocks or slowdowns, and the overall user experience. This process can be automated and integrated into your CI/CD pipeline, allowing for constant monitoring and immediate feedback on the impact of any code changes.
By implementing a robust testing framework that includes functional, unit, performance, and continuous synthetic tests, you can ensure that your API is not only reliable and performant but also offers a seamless experience for its consumers. And when issues do occur, this diversified testing approach can help you quickly locate and address the root cause.
2. Embrace Versioning
API versioning plays a crucial role in maintaining the reliability of software systems. As APIs evolve over time, changes can be introduced that could potentially break existing client applications if not managed properly. That's where API versioning comes in. By maintaining different versions of your API, you can introduce new features, improvements, or changes without negatively impacting applications that depend on previous API versions.
This practice promotes reliability as it ensures that client applications can continue to function predictably even as the API changes and evolves. It allows developers to deploy updates to the API without fear of introducing breaking changes to live applications, thus maintaining system stability and uptime.
Backward compatibility is an important aspect of this reliability. It's the ability of newer systems to interact with older versions of an API. Maintaining backward compatibility means that applications using older API versions continue to function even when newer versions are introduced. It prevents disruptions to the user experience and gives developers time to update their applications to accommodate new API changes at their own pace, rather than being forced to do so at the risk of application failure. This results in an overall more reliable, robust and resilient system.
Example
In Go, there are a few different ways you can handle versioning for your APIs.
Here's an example of how you might accomplish this by embedding the API version in the URL. This approach is often referred to as "path versioning".
package main
import (
"fmt"
"net/http"
)
func handleRequest(w http.ResponseWriter, r *http.Request) {
switch r.URL.Path {
case "/v1/users":
fmt.Fprintf(w, "You've hit the version 1 of the users API!")
case "/v2/users":
fmt.Fprintf(w, "You've hit the version 2 of the users API!")
default:
http.NotFound(w, r)
}
}
func main() {
http.HandleFunc("/", handleRequest)
http.ListenAndServe(":8080", nil)
}
In this example, we define a single handler function that switches on the requested URL. When the /v1/users path is accessed, we consider that to be a request for the first version of our API. Similarly, /v2/users corresponds to the second version of our API. By adding more cases, you can easily extend this pattern to additional versions and endpoints.
Alternatively, you could achieve versioning via custom headers or media type versioning (also known as "content negotiation").
It's crucial to note that irrespective of the method you choose, maintaining clear and up-to-date documentation for each version of your API is a best practice.
However, versioning should be used judiciously. Keep backward compatibility as long as possible and provide clear documentation about what changes in each new version, along with a reasonable timeline for deprecating older versions.
3. Design for Failures
In a perfect world, APIs would work flawlessly all the time. In reality, failures can and do happen. It's important to design your APIs with fault tolerance in mind. This could involve strategies such as graceful degradation (where the system continues to operate, but with reduced functionality) or failover mechanisms (where the operation is switched to backup systems in the event of a failure).
Including well-defined error messages and codes in your API can help consuming applications understand what went wrong and how to react. Retry logic, rate limiting, and circuit breakers can help systems recover from temporary issues and avoid cascading failures.
Example: Circuit Breaker Pattern
As for the circuit breaker pattern, there's a popular library in Go called go-hystrix which is a latency and fault tolerance library. The idea is to stop cascading failures by failing fast when services are down. Here's a basic example:
package main
import (
"github.com/afex/hystrix-go/hystrix"
"log"
"net/http"
"errors"
)
func main() {
hystrix.ConfigureCommand("my_command", hystrix.CommandConfig{
Timeout: 1000,
MaxConcurrentRequests: 100,
ErrorPercentThreshold: 25,
})
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
err := hystrix.Do("my_command", func() error {
// talk to other services
return nil
}, nil)
if err != nil {
log.Printf("Failed to talk to other services: %v", err)
http.Error(w, "Failed to talk to other services", http.StatusInternalServerError)
}
})
log.Fatal(http.ListenAndServe(":1234", nil))
}
In the example above, we have a command wrapped in hystrix.Do(). If the function passed into Do() fails or times out based on our configuration, it will trip the circuit breaker and further calls will fail immediately without calling the function.
Remember, this is just a basic examples and real-world usage will involve more complex usage and careful tuning of the various parameters involved in this library and other resiliency utility libraries . Be sure to read through the documentation of the various libraries to thoroughly understand how to utilize them effectively in your own code.
4. Monitor and Analyze
Nothing beats the power of real-time monitoring and timely analysis when it comes to maintaining API reliability. Implementing a solid API monitoring strategy that includes uptime, performance, and error detection can help identify and mitigate issues before they affect users.
Analysis of API usage patterns can also be extremely insightful. By understanding peak load times, most commonly used endpoints, and other usage details, you can proactively identify potential weak points and optimize your API accordingly.
Tracking the right metrics is crucial for understanding the health and performance of your API. Here are some of the key metrics you should consider:
Throughput: The number of requests that your API is handling per unit of time. This can be further broken down by endpoint, HTTP method (GET, POST, PUT, DELETE, etc.), or response status code.
Error Rate: The number of error responses (typically responses with a 4xx or 5xx status code) per unit of time. Like throughput, this can be further broken down by endpoint, HTTP method, or specific status code.
Latency: The amount of time it takes to serve a request. This is often tracked as a set of percentiles (like the 50th, 95th, and 99th percentiles), which can give you a sense of both typical and worst-case performance. You may want to track this separately for different endpoints or HTTP methods.
Traffic: The amount of data being sent and received. This can be broken down by endpoint, HTTP method, or response status code.
Availability: The percentage of time that your API is up and able to handle requests. This can be measured overall, or for individual endpoints.
Saturation: How close your system is to its maximum capacity. This could be measured in terms of CPU usage, memory usage, disk I/O, or any other resource that could potentially limit your system's ability to handle more load.
Circuit Breaker Trips: If you're using the circuit breaker pattern to handle failures, you might track how often the circuit breaker is tripped. This can give you a sense of how often your API or its dependencies are failing.
Remember, the specific metrics you choose to track may vary depending on the nature of your API and the needs of your application. The key is to choose metrics that give you meaningful insight into the health and performance of your API.
Example with Prometheus:
Prometheus, an open-source systems monitoring and alerting toolkit, has client libraries that allow you to instrument your services in a variety of languages. Here's an example of how you might use the Go client library to expose metrics on an HTTP endpoint.
We will leverage the prometheus go client to expose metrics and create them.
package main
import (
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
httpRequestsTotal = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Number of HTTP requests",
},
[]string{"path"},
)
httpRequestDuration = prometheus.NewSummaryVec(
prometheus.SummaryOpts{
Name: "http_request_duration_seconds",
Help: "Duration of HTTP requests in seconds",
},
[]string{"path"},
)
)
func init() {
// Register the metrics.
prometheus.MustRegister(httpRequestsTotal)
prometheus.MustRegister(httpRequestDuration)
}
func handler(w http.ResponseWriter, r *http.Request) {
// Increment the counter for the received requests.
httpRequestsTotal.WithLabelValues(r.URL.Path).Inc()
// Measure the time it took to serve the request.
timer := prometheus.NewTimer(httpRequestDuration.WithLabelValues(r.URL.Path))
defer timer.ObserveDuration()
// Handle the request.
w.Write([]byte("Hello, world!"))
}
func main() {
http.HandleFunc("/", handler)
// Expose the registered metrics via HTTP.
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":8080", nil)
}
In this example, we create and register two metrics: http_requests_total and http_request_duration_seconds. The former is a counter that increments every time a request is received, while the latter is a summary that records the duration it takes to serve each request.
We then create an HTTP handler that increments the counter and measures the request duration every time it handles a request. We expose these metrics at the /metrics endpoint using the promhttp.Handler().
Now, if you start the server and make requests to it, you can see the metrics by navigating to http://localhost:8080/metrics in your web browser or using a tool like curl.
This is a simple example and in a real-world application, you would probably want to track more metrics and perhaps break them down by other dimensions such as HTTP method, response status code, etc.
5. Leverage API Gateway
API gateways are powerful tools for improving API reliability. They act as a single point of entry into a system and can handle a multitude of functions like routing, load balancing, authentication, rate limiting, and more. By abstracting these concerns away from the API itself, you can focus more on business logic and less on infrastructure.
Moreover, API gateways can provide additional resiliency features, such as automatic failover, caching responses for faster performance, and buffering or queueing requests during high load periods.
Here are some of the common features provided by API Gateways; this list of features is by no means exhaustive, but it would help you choose an API gateway for your stack:
Request Routing: API Gateways route client requests to appropriate back-end services based on the route specified in the request.
API Version Management: API Gateways can manage multiple versions of an API, allowing clients to use different versions concurrently.
Rate Limiting: To protect back-end services from being overwhelmed by too many requests, API Gateways can limit the rate of incoming requests from a client or a group of clients.
Authentication and Authorization: API Gateways often handle the authentication and authorization of client requests, ensuring only valid and authorized requests reach the back-end services.
API Key Management: API Gateways often manage API keys, which are used to track and control how the API is being used.
Caching: To improve performance and reduce the load on back-end services, API Gateways can cache responses from back-end services and serve cached responses when the same requests are made.
Request and Response Transformation: API Gateways can transform requests and responses to a format expected by clients or back-end services.
Circuit Breaker Functionality: In the case of a service failure, API Gateways can prevent application failure by routing requests away from the failing service.
Monitoring and Analytics: API Gateways can collect data on API usage and performance, which can be used for analytics, monitoring, and alerting.
Security Policies: API Gateways can enforce security policies, such as IP whitelisting, and protect against attacks like SQL Injection and Cross-Site Scripting (XSS).
Here's a list of some popular open-source API gateway:
Kong: A cloud-native, fast, scalable, and distributed Microservice Abstraction Layer (also known as an API Gateway or API Middleware). Made available as an open-source project in 2015, its core functionality is written in Lua and it runs on the nginx web server.
Tyk: An open-source API Gateway that is fast and scalable, running on either its own standalone server or alongside your existing nginx installation.
Express Gateway: A microservices API Gateway built on Express.js. It's entirely extensible and framework agnostic, delivering robust, scalable solutions in no time.
KrakenD: A high-performance open-source API Gateway. It helps application developers release features quickly by eliminating all the complexities of SOA architectures while offering a unique performance.
In conclusion, improving API reliability is not a one-off task but an ongoing commitment. It involves rigorous testing, sound design principles, smart use of tools like API gateways, and constant monitoring and analysis. With these strategies, you can build APIs that stand the test of time and serve as reliable foundations for your applications.
Enjoyed this article and want more of the same? We'd love to keep sharing our insights with you!