
Slow Down! Rate Limiting Deep Dive

In one of the previous posts we talked about Eight Pillars of Fault-tolerant Systems series. In this post let's discuss the importance and implementation of rate limiting mechanisms to improve the API reliability.
What exactly is rate limiting? It's a control mechanism that dictates how often a user can call your API within a certain time frame.
Now, why should you care about rate limiting? Well, consider a situation where your API is hit with a massive number of requests in a short span. This could be due to a surge in user traffic, a glitch causing repeated requests, or even an attempt to overwhelm your system using DDOS attack. Without rate limiting, your system could get overwhelmed, leading to slow responses or, worse, a complete service disruption.
But the benefits of rate limiting extend beyond just protecting your system. It's also a tool for managing service usage. It helps in enforcing API usage policies, monitoring API quotas, and even offering tiered usage plans to customers. Simply put, rate limiting is a key player in efficient API management.
Types of Rate Limiting
Different algorithms can be used to implement rate limiting. Let's review the most common types in this section.
Fixed Window Counter
Fixed Window Rate Limiting works by dividing time into fixed windows and allowing a certain number of requests in each window. For example, if we have a limit of 100 requests per hour, and our window starts at 2:00, we can make 100 requests between 2:00 and 3:00.
However, if we make all 100 requests at 2:10, we will have to wait until 3:00 to make another request. This can lead to uneven distribution of requests, with potential for bursts of traffic at the start of each window.

Let's now look at how we can implement this in Java. We'll use a HashMap to store the timestamp of the window start and a counter for the number of requests.
import java.util.HashMap;
import java.util.Map;
public class RateLimiter {
private final int maxRequestPerWindow;
private final long windowSizeInMillis;
private final Map<String, Window> store = new HashMap<>();
public RateLimiter(int maxRequestPerWindow, long windowSizeInMillis) {
this.maxRequestPerWindow = maxRequestPerWindow;
this.windowSizeInMillis = windowSizeInMillis;
}
public synchronized boolean isAllowed(String clientId) {
long currentTimeMillis = System.currentTimeMillis();
Window window = store.get(clientId);
// If the window doesn't exist or has expired, create a new window
if (window == null || window.getStartTime() < currentTimeMillis - windowSizeInMillis) {
window = new Window(currentTimeMillis, 0);
}
// Check if the number of requests in the window exceeds the maximum allowed
if (window.getRequestCount() >= maxRequestPerWindow) {
return false; // Request is not allowed
}
// Increment the request count and update the window in the store
window.setRequestCount(window.getRequestCount() + 1);
store.put(clientId, window);
return true; // Request is allowed
}
private static class Window {
private final long startTime;
private int requestCount;
public Window(long startTime, int requestCount) {
this.startTime = startTime;
this.requestCount = requestCount;
}
public long getStartTime() {
return startTime;
}
public int getRequestCount() {
return requestCount;
}
public void setRequestCount(int requestCount) {
this.requestCount = requestCount;
}
}
}
In the above code, we first define the maximum number of requests allowed per window (maxRequestPerWindow) and the window size in milliseconds (windowSizeInMillis).
The isAllowed method checks if a request from a client is allowed. If the client's window does not exist or has expired, a new window is created. If the number of requests in the window exceeds the maximum allowed, the method returns false, indicating that the request is not allowed. Otherwise, the request count is incremented, and the method returns true.
Sliding window counter
The Sliding Window algorithm improves upon the Fixed Window algorithm by providing a more evenly distributed control of requests. Instead of allowing the entire limit of requests at the start of the window, the Sliding Window algorithm distributes the allowance throughout the window.

The Sliding Window algorithm works by keeping track of the timestamp of each request in a rolling time window. The server maintains a count of requests for each client and the timestamp of their oldest request. When a new request comes in, the server checks the count of requests in the sliding window. If the count exceeds the limit, the server denies the request.
import java.util.Deque;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentLinkedDeque;
public class SlidingWindowRateLimiter {
private final int maxRequests;
private final long windowSizeInMillis;
private final ConcurrentHashMap<String, Deque<Long>> timestamps = new ConcurrentHashMap<>();
public SlidingWindowRateLimiter(int maxRequests, long windowSizeInMillis) {
this.maxRequests = maxRequests;
this.windowSizeInMillis = windowSizeInMillis;
}
public boolean isAllowed(String clientId) {
// Get the timestamp deque for the client, creating a new one if it doesn't exist
Deque<Long> clientTimestamps = timestamps.computeIfAbsent(clientId, k -> new ConcurrentLinkedDeque<>());
// Get the current timestamp in milliseconds
long currentTimeMillis = System.currentTimeMillis();
// Remove timestamps older than the sliding window
while (!clientTimestamps.isEmpty() && currentTimeMillis - clientTimestamps.peekFirst() > windowSizeInMillis) {
clientTimestamps.pollFirst();
}
// Check if the number of requests in the sliding window exceeds the maximum allowed
if (clientTimestamps.size() < maxRequests) {
clientTimestamps.addLast(currentTimeMillis);
return true; // Request is allowed
}
return false; // Request is not allowed
}
}
The isAllowed method checks if a request from a client is allowed. It first removes timestamps that are outside the sliding window. If the number of requests in the window exceeds the maximum allowed, the method returns false, indicating that the request is not allowed. Otherwise, the current timestamp is added to the deque, and the method returns true.
Token Bucket
Token Bucket is a widely used algorithm for rate limiting that provides a more precise and controlled way of allowing requests. It works by maintaining a "bucket of tokens", where each token represents the capacity to execute a single request. Clients are allowed to make requests as long as tokens are available in the bucket. When a request is made, a token is consumed from the bucket. If no tokens are available, the request is dropped until tokens become available.
The Token Bucket algorithm is based on the concept of a refill rate, which determines the rate at which tokens are added to the bucket over time. This refill rate ensures that the bucket is replenished with tokens at a consistent pace, enabling a smooth and controlled flow of requests.

Now that we understand the Token Bucket algorithm, let's proceed with its implementation in Java:
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.atomic.AtomicLong;
public class TokenBucketRateLimiter {
private final long capacity;
private final AtomicLong tokens;
private final Duration refillPeriod;
private volatile Instant lastRefillTime;
public TokenBucketRateLimiter(long capacity, Duration refillPeriod) {
this.capacity = capacity;
this.tokens = new AtomicLong(capacity);
this.refillPeriod = refillPeriod;
this.lastRefillTime = Instant.now();
}
public synchronized boolean isAllowed() {
refillTokens();
long currentTokens = tokens.get();
if (currentTokens > 0) {
tokens.decrementAndGet();
return true; // Request is allowed
}
return false; // Request is not allowed
}
/**
* Refills tokens in the token bucket based on the refill period.
*/
private synchronized void refillTokens() {
Instant now = Instant.now();
long timeElapsed = Duration.between(lastRefillTime, now).toMillis();
long tokensToAdd = timeElapsed / refillPeriod.toMillis();
if (tokensToAdd > 0) {
lastRefillTime = now;
tokens.getAndUpdate(currentTokens -> Math.min(capacity, currentTokens + tokensToAdd));
}
}
}
Here's an explanation of the key components:
capacityrepresents the maximum number of tokens the bucket can hold.tokensis anAtomicLongthat keeps track of the number of available tokens in the bucket.refillPeriodis the duration between token refills.lastRefillTimestores the instant of the last token refill.
The isAllowed method is responsible for determining if a request is allowed based on the availability of tokens. It first calls refillTokens to ensure the bucket is replenished. If tokens are available, the method decrements the token count and returns true. Otherwise, it returns false.
The refillTokens method calculates the elapsed time since the last refill and adds tokens based on the refill period. It updates the last refill time
Leaky Bucket
The Leaky Bucket algorithm is a rate limiting technique that controls the flow of requests by smoothing out the traffic. Requests are released from the bucket at a fixed rate, resembling water leaking out of a bucket at a steady pace. If the bucket becomes full, additional incoming requests are either discarded or delayed.
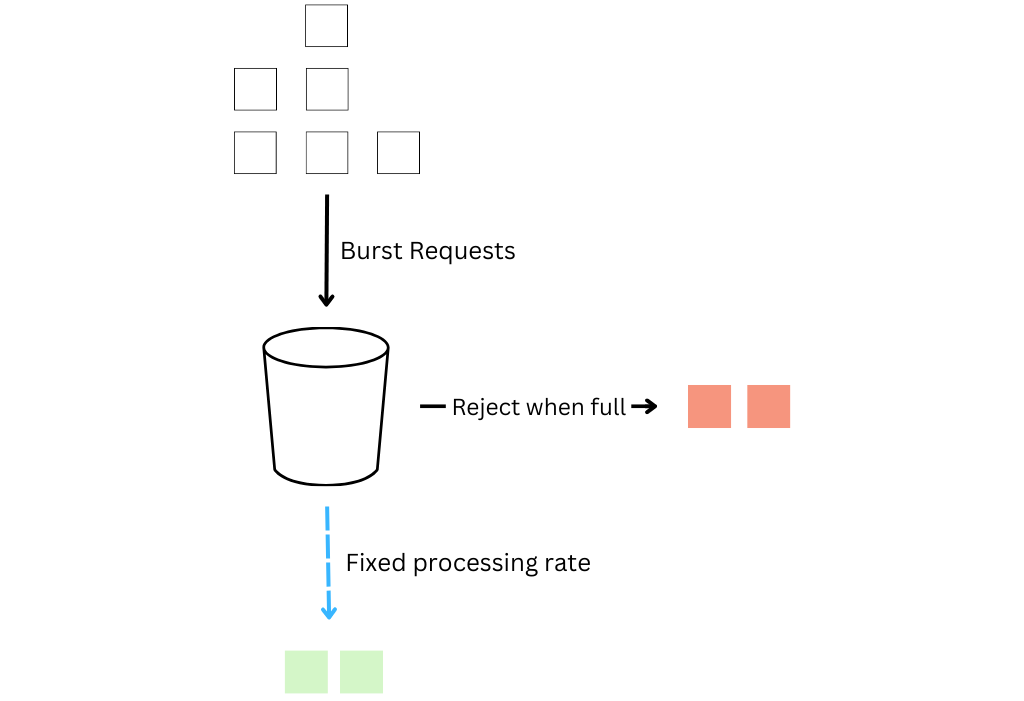
The Leaky Bucket algorithm provides a controlled and consistent rate of request processing, regardless of the incoming request rate. It helps prevent sudden bursts of traffic and ensures a smoother flow of requests.
import java.time.Duration;
import java.util.concurrent.atomic.AtomicLong;
public class LeakyBucketRateLimiter {
private final long capacity;
private final long ratePerSecond;
private final AtomicLong lastRequestTime;
private final AtomicLong currentBucketSize;
public LeakyBucketRateLimiter(long capacity, long ratePerSecond) {
this.capacity = capacity;
this.ratePerSecond = ratePerSecond;
this.lastRequestTime = new AtomicLong(System.currentTimeMillis());
this.currentBucketSize = new AtomicLong(0);
}
public synchronized boolean isAllowed() {
long currentTime = System.currentTimeMillis();
long elapsedTime = currentTime - lastRequestTime.getAndSet(currentTime);
// Calculate the amount of tokens leaked since the last request
long leakedTokens = elapsedTime * ratePerSecond / 1000;
currentBucketSize.updateAndGet(bucketSize ->
Math.max(0, Math.min(bucketSize + leakedTokens, capacity)));
// Check if a request can be processed by consuming a token from the bucket
if (currentBucketSize.get() > 0) {
currentBucketSize.decrementAndGet();
return true; // Request is allowed
}
return false; // Request is not allowed
}
}
capacityrepresents the maximum number of requests that the bucket can hold.ratePerSecondspecifies the rate at which requests are released from the bucket.lastRequestTimeis anAtomicLongthat stores the timestamp of the last processed request.currentBucketSizeis anAtomicLongthat tracks the current number of requests in the bucket.
isAllowed calculates the elapsed time since the last request and determines the number of tokens leaked from the bucket. The current bucket size is adjusted accordingly. If the bucket contains any tokens, a request is allowed by consuming a token from the bucket. Otherwise, the request is rejected.
Application Design Considerations
When working with APIs that impose rate limits, it is important to design your applications with rate limiting in mind. Here are some key considerations:
Implement and Monitor Rate Limit Headers - APIs often include rate limit information in the response headers. It's essential to monitor these headers, such as
X-RateLimit-Limit,X-RateLimit-Remaining, andX-RateLimit-Reset, to know the current rate limit, remaining requests, and the time when the rate limit resets. This information helps you stay within the allowed limits and handle rate limit errors gracefully.Implement Backoff and Retry Mechanisms - When you encounter a rate limit error, instead of immediately giving up, implementing a backoff and retry mechanism is a recommended approach. Backoff refers to introducing a delay between retries to avoid overwhelming the API further. Consider using exponential backoff, where the delay between retries increases exponentially with each subsequent attempt.
Prioritize Critical Requests - Not all API requests are equal in terms of importance. Identify critical requests that must go through even during rate limits, and prioritize them accordingly. This can help ensure that essential operations are not hindered by rate limits.
Informative Error Messages - When a rate limit is exceeded, provide clear and informative error messages to users. Explain the reason for the error and provide guidance on how to resolve it. This helps users understand the issue and take appropriate action.
Graceful Degradation - Implement graceful degradation when rate limits are reached. Instead of completely blocking users, consider offering limited functionality or alternative options to keep the application usable. Check out this post we have on this topic
Conclusion
Rate limiting is a powerful tool that ensures the smooth operation of APIs and protects them from various threats. By understanding its mechanics, implementing effective strategies, and considering the impact on users we can build reliable and scalable systems.